Blog
Gathering Core Web Vitals Data using Asynchronous Python Code
Simran Gill
21 April 2026
With Core Web Vitals becoming a ranking factor in May 2021, being able to gather quick and up-to-date web vitals data has never been more important. Within this blog post I will be giving an overview of how to quickly gather web vitals data for a list of URL’s using the PageSpeed Insights (PSI) API and asynchronous python code.
We will be specifically pulling all page timing metrics and the top level category scores.
Accessing the PSI API
For testing or very low volume usage no authentication is required to run a test and gather insights. Feel free to run a quick curl on or copy the following URL into your browser if you don’t believe me :
https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=https://developers.google.com
You should have been met with a fairly hefty JSON response which we will parse later on.
PageSpeed Insights actually uses Lighthouse to power it. This means we can extract all the information in a Lighthouse report from the PSI API.
Now, as we will be running our code on a list of URLs and requesting data asynchronously it is likely we will need to authenticate our API calls to minimise our chances of hitting any rate limits.
In order to gain an API key to use with our requests we will need to go through google developers console. Once we have our key we can simply append it to the example URL above.
Simply follow the steps below in order to gain your API key.
- Go to Google Developers Console.
- Create a New Project if you haven’t got one set up already.
- In the sidebar on your left make sure you’re in the APIs and Services dashboard for your project.
- Select +ENABLE APIS AND SERVICES at the top of the page.
- Search for the PageSpeed Insights API, click on it and then enable it.
- Now use the hamburger menu in the top left to navigate to the credentials section of APIs and Services.
- Here select +CREATE CREDENTIALS at the top of the page and select API key.
- Simply copy this and keep it for later.
Now you have access to the higher rate limits for the PSI API we can start coding.
The URL’s I will be using to gather data on come from the organic results on the first SERP for the search term “car leasing”. I will be pulling data for both desktop and mobile SERPs, with the pages being rendered for their appropriate device by the PSI API. This means we will have around 20 API pulls to perform.
Synchronous Data Pulls
Writing synchronous code means doing one thing after another. If you want to perform a GET request on each URL in a list of URLs you could set up a simple for loop to do so. You will start with the first in the list, perform the request, get the response, do whatever you want to with that response and then move on to the second URL in our list of URLs. This process would then repeat with each request being performed, only after the previous request has completed and the response has been handled, until we’ve been through our whole URL list.
Generally, running 20 API calls to gather data in this way wouldn’t be that much of a burden. So lets try out a quick script with our PSI API.
import requests
import time
def PSI(mobile_desktop, url):
api_url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url="+url+"&key=YOUR_API_KEY&strategy="+mobile_desktop+"&category=performance&category=accessibility&category=best-practices&category=seo"
response = requests.get(api_url)
result = response.json()
return result
if __name__ == "__main__":
start = time.time()
desktop_url_list = ['https://www.selectcarleasing.co.uk/',
'https://www.nationwidevehiclecontracts.co.uk/car-leasing/deals',
'https://www.firstvehicleleasing.co.uk/car-leasing',
'https://www.carwow.co.uk/car-leasing',
'https://www.synergycarleasing.co.uk/top-20-lease-deals/',
'https://www.whatcar.com/car-leasing/',
'https://leasing.com/car-leasing/',
'https://www.leasingoptions.co.uk/car-leasing',
'https://www.pinkcarleasing.co.uk/special-car-leasing-deals',
'https://www.contractcars.com/']
mobile_url_list = ['https://www.selectcarleasing.co.uk/',
'https://www.nationwidevehiclecontracts.co.uk/car-leasing/deals',
'https://www.carwow.co.uk/car-leasing',
'https://www.firstvehicleleasing.co.uk/car-leasing',
'https://www.synergycarleasing.co.uk/top-20-lease-deals/',
'https://www.whatcar.com/car-leasing/',
'https://leasing.com/car-leasing/',
'https://www.leasingoptions.co.uk/car-leasing',
'https://www.pinkcarleasing.co.uk/special-car-leasing-deals',
'https://www.hippoleasing.co.uk/personal-lease-cars/']
results = []
for desktop_url in desktop_url_list:
desktop_json = PSI("desktop", desktop_url)
results.append(desktop_json)
for mobile_url in mobile_url_list:
mobile_json = PSI("mobile", mobile_url)
results.append(mobile_json)
end = time.time()
print("Sync Time Taken = "+str(end-start))Let’s break the code down.
We’re importing the requests library, in order to send GET requests to the PSI API, and the time library in order to measure how long our script takes. We then have the PSI function that takes “mobile” or “desktop” as an argument, depending on which device you want to test the target page against, and an input URL. Within the function, we are building our request to the PSI API and then sending a GET request to our newly built URL. We then receive a JSON response and are simply returning the JSON for the time being.
Within this function you may notice our request PSI URL is a little longer than the initial test URL at the beginning of this blog post. This is because in order to get the overall scores for SEO, Performance etc. that you see on lighthouse , we need to request them explicitly, hence the extra category URL parameters you see in this function.
We then write some code to use this function. We first make a note of what time we start. Then we are then taking our desktop and mobile URLs and are simply passing them through our PSI function, with the appropriate device specified, in two simple for loops and waiting for them to all pull through. We make a note of the final time and find the difference to see how long this took us in seconds.
The output to our script can be seen below. Sync Time Taken = 448.24924063682556
We can see the script took 448 seconds to run through 19 pages. That’s 7 minutes and 28 seconds.
The reason for this sluggish performance is the fact that the PSI API is rendering your input page and performing various tests and checks on it then and there. Great for up to date data but bad for bulk performance.
Lets see if we can speed this up by using asynchronous code.
Asynchronous Data Pulls
In our synchronous example we had to wait for each API request to complete, and the response to be handled, before we could then move onto the next page to request. We can actually write our code in such a way that after we send off the first request to our API, while we’re waiting for that request to complete, we can send off the next API request. Then as we’re waiting for that request to complete we can send off the request for our next one. This means we can have the PSI API rendering and testing multiple pages at the same time. This should dramatically speed up our work flow.
Lets go through this scripting in a little more detail than our synchronous script.
Let’s start with our imports.
import asyncio
import time
import pandas as pd
from aiohttp import ClientSession, ClientTimeoutAsyncio lets us write concurrent code and will enable us to request multiple page tests at once. Time is used again to time how long our pulls take. Pandas will be used to produce our final dataframe of data. Aiohttp provides an asynchronous HTTP Client for asyncio and is in place of the requests module in our synchronous example. This will allow us to send asynchronous GET requests to the PSI API.
Now lets build our PSI class to handle all things PSI related.
class PSI():
def __init__(self, url_list):
self.url_list = url_list
def desktop_urls(self):
base_url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=++url++&key=YOUR_API_KEY&strategy=desktop&category=performance&category=accessibility&category=best-practices&category=seo"
desktop_urls = [base_url.replace("++url++", url) for url in self.url_list]
return desktop_urls
def mobile_urls(self):
base_url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=++url++&key=YOUR_API_KEY&strategy=mobile&category=performance&category=accessibility&category=best-practices&category=seo"
mobile_urls = [base_url.replace("++url++", url) for url in self.url_list]
return mobile_urlsFor the PSI class we will initialize it with a list of URLs we want page speed data on. We also have some basic functions to generate either a list of mobile rendered PSI URLs or desktop rendered URLs.
class PSI():
.
.
.
async def fetch(self, url, session):
async with session.get(url) as response:
response = await response.json()
return response
async def build_futures(self, urls):
futures = []
async with ClientSession() as session:
for url in urls: #build a list of futures for async to run
task = asyncio.ensure_future(self.fetch(url, session))
futures.append(task)
responses = await asyncio.gather(*futures) # run all future - returns response bodies
return responses
def get_responses(self, urls):
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(self.build_futures(urls))
jsons = loop.run_until_complete(future)
return jsonsNow we will append our asynchronous code to our PSI class. We have a fetch async function and a build_futures async function.
Our fetch function takes a PSI URL and a client session as an argument. It then sends a get request to our PSI URL via our client and waits for the response.
Next we have our build_futures async function. Here we are looping through our page URLs and using ensure_future to build a list of awaitable coroutine functions that are then scheduled as tasks and are ran concurrently. We use asyncio.gather to run our awaitables. Here we are returning a list of responses from our tasks. This will be a list of JSONs that we need to parse and pull data from.
We then have our final function to pull our data. The get_responses function. This basically starts off our async loop and then stops it only once its complete and we have our list of JSONs.
Now let’s finish our data puller with a parser to parse our JSON.
class PSI():
.
.
.
def analyze_jsons(self, json_list):
all_data = []
for json in json_list:
device = json.get('lighthouseResult',{}).get('configSettings',{}).get('emulatedFormFactor',"NA")
page = json.get('id',"NA")
performance = float(json.get('lighthouseResult',{}).get('categories',{}).get('performance',{}).get('score',"NA"))
accessibility = float(json.get('lighthouseResult',{}).get('categories',{}).get('accessibility',{}).get('score',"NA"))
best_practices = float(json.get('lighthouseResult',{}).get('categories',{}).get('best-practices',{}).get('score',"NA"))
seo = float(json.get('lighthouseResult',{}).get('categories',{}).get('seo',{}).get('score',"NA"))
first_contentful = float(json.get('lighthouseResult',{}).get('audits',{}).get('first-contentful-paint',{}).get('numericValue',"NA"))
speed_index = float(json.get('lighthouseResult',{}).get('audits',{}).get('speed-index',{}).get('numericValue',"NA"))
total_blocking_time = float(json.get('lighthouseResult',{}).get('audits',{}).get('total-blocking-time',{}).get('numericValue',"NA"))
cumulative_layout_shift = float(json.get('lighthouseResult',{}).get('audits',{}).get('cumulative-layout-shift',{}).get('numericValue',"NA"))
interactive = float(json.get('lighthouseResult',{}).get('audits',{}).get('interactive',{}).get('numericValue',"NA"))
largest_contentful = float(json.get('lighthouseResult',{}).get('audits',{}).get('largest-contentful-paint',{}).get('numericValue',"NA"))
all_data.append([device,page,performance,accessibility,best_practices,seo,first_contentful,interactive,largest_contentful,speed_index,total_blocking_time,cumulative_layout_shift])
return all_dataHere we are looking at lab results rather than field results. Some pages don’t have enough traffic to collect field results however feel free to add in logic and explore the JSON the PSI API returns in order to return the exact information you want.
Here we are pulling out:
- Device
- Page
- Performance score (out of 1)
- Accessibility score (out of 1)
- Best Practices score (out of 1)
- SEO score (out of 1)
- First Contentful Paint
- Speed Index
- Total Blocking Time
- Cumulative Layout Shift
- Time to Interactive
- Largest Contentful paint.
Some metrics aren’t available for certain pages so they need to be handled, here we return NA for any missing values. Finally let’s utilise this class to pull our data and time how long this takes.
if __name__ == "__main__":
start = time.time()
desktop_url_list = ['https://www.selectcarleasing.co.uk/',
'https://www.nationwidevehiclecontracts.co.uk/car-leasing/deals',
'https://www.firstvehicleleasing.co.uk/car-leasing',
'https://www.carwow.co.uk/car-leasing',
'https://www.synergycarleasing.co.uk/top-20-lease-deals/',
'https://www.whatcar.com/car-leasing/',
'https://leasing.com/car-leasing/',
'https://www.leasingoptions.co.uk/car-leasing',
'https://www.pinkcarleasing.co.uk/special-car-leasing-deals',
'https://www.contractcars.com/']
mobile_url_list = ['https://www.selectcarleasing.co.uk/',
'https://www.nationwidevehiclecontracts.co.uk/car-leasing/deals',
'https://www.carwow.co.uk/car-leasing',
'https://www.firstvehicleleasing.co.uk/car-leasing',
'https://www.synergycarleasing.co.uk/top-20-lease-deals/',
'https://www.whatcar.com/car-leasing/',
'https://leasing.com/car-leasing/',
'https://www.leasingoptions.co.uk/car-leasing',
'https://www.pinkcarleasing.co.uk/special-car-leasing-deals',
'https://www.hippoleasing.co.uk/personal-lease-cars/']
desktop_data_puller = PSI(desktop_url_list)
mobile_data_puller = PSI(mobile_url_list)
desktop_urls = desktop_data_puller.desktop_urls()
mobile_urls = mobile_data_puller.mobile_urls()
all_urls = desktop_urls + mobile_urls
jsons = desktop_data_puller.get_responses(all_urls)
results = desktop_data_puller.analyze_jsons(jsons)
results_df = pd.DataFrame.from_records(results, columns=['device','link','performance','accessibility','best_practices','seo','first_contentful','interactive','largest_contentful','speed_index','total_blocking_time','cumulative_layout_shift'])
end = time.time()
print("Async time = "+str(end-start))Running this script gives the output below.
Async time = 32.802369117736816
Here we can see the script finished in 33 seconds. This is only 7% of the original synchronous pull. Almost 7 minutes faster, a significant time saving. Depending on your use case you may be pulling even more PSI Tests and the time saving will be even greater.
Our results_df, that stores our data, also looks like this.

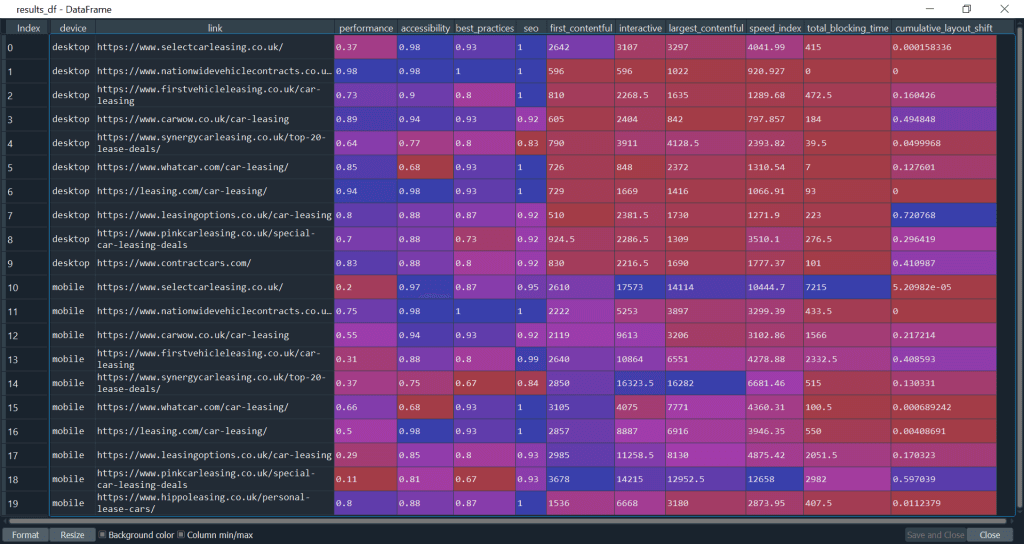
Here we have enough data to see which pages on the SERP are performing the best. We can also see which could , and should, be improved upon before the May 2021 Google update.
Final Thoughts
The above sample scripting forms a good basis for pulling our core web vitals data fast. This method could be used to identify where your pages sit against specific SERPs. It could also be used, along with a crawl, to identify slow pages on your site.
Having said this, the above scripting could be improved to handle any rate limits or server issues the API may have. Other errors may pop up depending on the URLs being pulled which would also need to be handled. As we are also testing pages on the fly it may also be useful to implement multiple tests and averaging them in order to dull the impacts of any outliers.
To further discuss any of of the tips or content highlighted within this post, get in touch with our senior team for a free 1-to-1 consultation – [email protected]!
Written by
Simran Gill
Latest posts.




Contact.
We’re always keen to talk search marketing.
We’d love to chat with you about your next project and goals, or simply share some additional insight into the industry and how we could potentially work together to drive growth.